class: center, middle # Kubernetes and Service Mesh Workshop .strong.footnote.left[Slides: https://slides.peterj.dev/jfuture-2019] --- ## Agenda ### Workshop runs from 12:00 PM to 5:00 PM - Lunch at 14:30 PM ### Multiple sections - theory + exercises - Introduction to Containers - Docker and Kubernetes - Istio Service Mesh - Traffic Routing - Resiliency - Security ??? --- ## Introduction - I am Peter ([@pjausovec](https://twitter.com/pjausovec)) - Software Engineer at Oracle - Working on "cloud-native" stuff - Books: - [Cloud Native: Using Containers, Functions, and Data to Build Next-Gen Apps](https://www.amazon.com/Cloud-Native-Containers-Next-Generation-Applications/dp/1492053821) - SharePoint Development - VSTO For Dummies - Courses: - Kubernetes Course ([https://startkubernetes.com](https://startkubernetes.com)) - Istio Service Mesh Course ([https://learnistio.com](https://learnistio.com)) --- name: intro background-image: url(./images/serverroom-old.jpg) background-size: cover .copyright[Source: https://www.sourcetoday.com/viewpoint/3-data-center-maintenance-tips-mitigate-security-threats] ??? Anyone knows what this is? - Older server room How did a companies like this one or any other bigger company scale in the past? **Buying more servers** --- background-image: url(./images/serverroom-new.png) background-size: cover .copyright[By helpameout - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=20337780] ??? A more modern data center or a service room. Buying servers costs $$ and it’s hard. How do you know how many servers you need? Do you buy more servers or less to save money? What happens if you buy less? Don't forget that it also takes time to set up all these server, to update them and to maintain them --- background-image: url(./images/thematrix.png) background-size: cover ??? In 2006 a company called VMWare comes along and says: “we have a thing called virtualization”. --- ## Virtualization - 2006: VMWare Server - Run multiple OS on the same host - Expensive: multiple kernels, OS ... ??? They released a product called VMWare Server and decided to give the virtualization technology to everyone for free. You can run multiple operating systems on the same host – on the same server/infrastructure. And the apps have no clue about each other, it’s pretty much like running a separate computer within a computer. This was also more efficient – you could run more apps on the existing servers you had. Virtualization is expensive – multiple kernels, multiple OS … you need to allocate resources for the virtual Oss – still not the best thing ever. --- background-image: url(./images/containers.png) background-size: cover ??? Fast forward to containerization and Docker. --- ## Docker - First public release in 2013 - Containers existed in Linux for >10 years - Slice the OS to securely run multiple applications - Namespaces, cGroups ??? First public release of Docker was in 2013. However, containers are not new and they existed in Linux for more than 10 years. The idea behind containerization is to slice up the OS so you can securely run multiple applications - this is done using Linux features of namespaces and cgroups. Docker uses images to create containers out of it. These images containing OSs are lightweight and portable, and everything is really fast – where you previously had to boot up the whole OS, with Docker you can spin it up within seconds. There’s also no hypervisor – there’s no separate kernel, it’s utilizing same resources as the host OS and it exploits namespaces and cGroups to use resources in more efficient way. - namespaces = allow you to slice different components of an OS and create isolated workspaces - cgroups = allow fine-grained control of resources (so one single container can't use up all system resources) --- class: pic 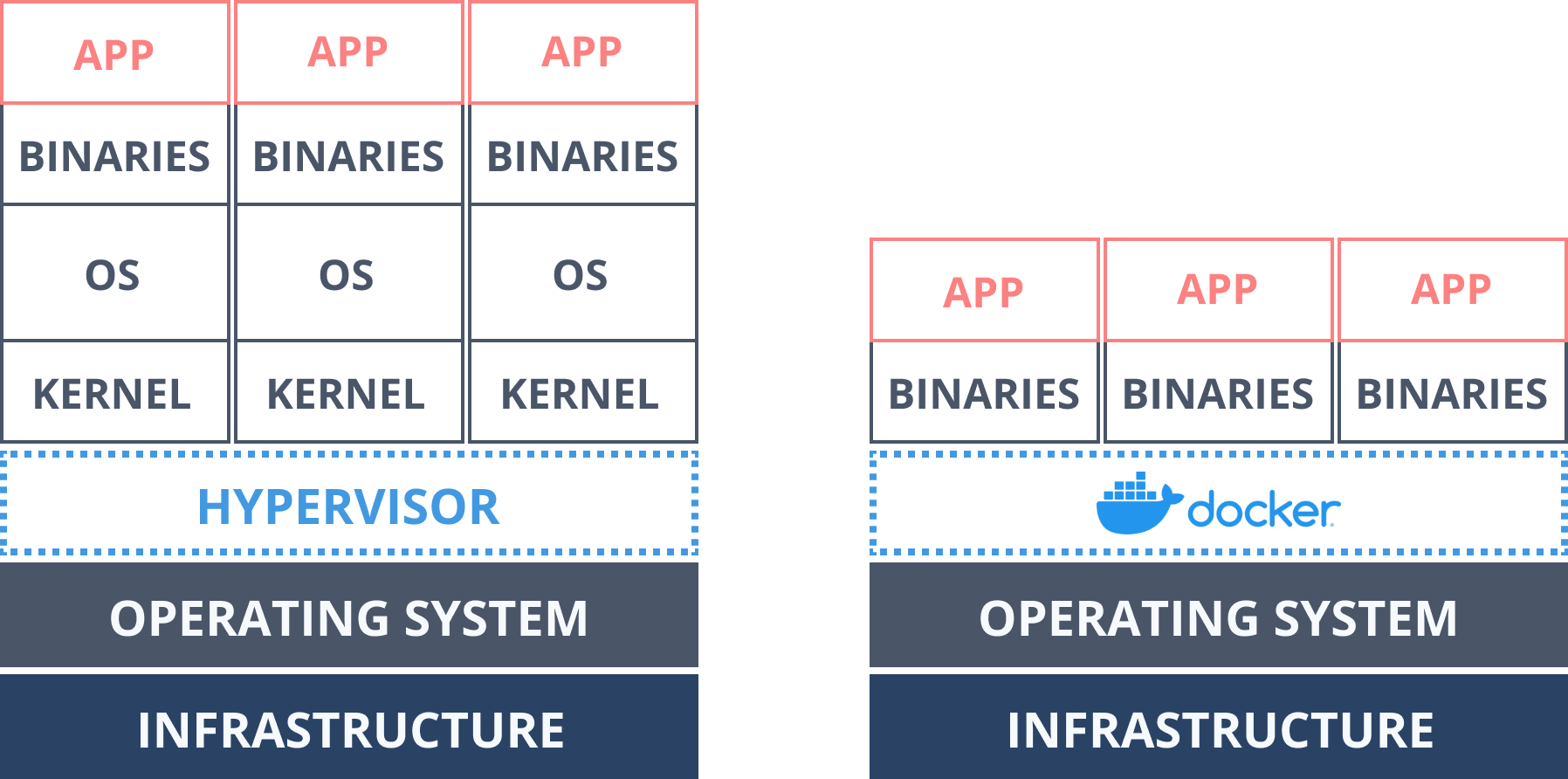 ??? Virtualization vs. containerization **Virtualization** Infrastructure == your server, bare metal, host, laptop, desktop OS == windows server, macos, linux Hypervisor == knows how to read the VM images (isolated environments inside of a file) –vmware, virtualbox Guest Operating Systems == each OS has it’s own kernel and this is where things get expensive in terms of resource allocation; on top of the OS is where you install your binaries **Containerization** - Infra + OS is the same - There’s no hypervisor, but docker daemon instead (process) – manages running containers, images, command line utils etc. The Docker images you run, are running directly on the host machine. A running instance of the image is called a container - contains the copy of your app/binaries etc. Docker is using cGroups and namespaces to use the resources directly from the machine. We are using the same kernel, but we are using namespaces to create segments that can be used and cGroups are defining how much of the resources (ram, network bandwidth …) you can use. --- class: pic  --- name: docker class: pic  --- class: center, middle # What is Docker? Docker Engine (daemon) + CLI --- ## Dockerfile ```line-numbers FROM ubuntu:18.04 WORKDIR /app COPY hello.sh /app RUN chmod +x hello.sh RUN apt-get update RUN apt-get install curl -y CMD ["./hello.sh"] ``` ??? The first thing you need to understand and know what is it, is a Dockerfile. Dockerfile is a set of instructions and commands that tell Docker how to create an image In this dockerfile we are creating a new image based on the existing Ubuntu image, we are setting the working directory, copying some files over to the image, running a couple of commans and finally setting the command to the script we copied in to the image. --- ## Docker image - Collection of layers from `Dockerfile` (one layer per command) - Layers are stacked on top of each other - Each layer is a delta from the layer before it - All layers are read-only ??? A docker image is a file that has a collection of layers and it's used to execute code in a Docker container. It's the product of a Dockerfile --- class: pic ## Docker image  ??? All the layers in the image read-only, with the exception of a top layer that gets created when you create a new container from the image. If we think about images as templates, then we can say that containers are instances of those templates. Any changes that you make to the running container (adding, modifying, deleting files etc.) is written on this writeable top layer. --- ## Image names - Image = repository + image name + tag <pre><code class="hljs">mycompany/hello-world:1.0.1 </code></pre> - All images get a default tag called _latest_ - Tag = version or variant of an image ??? Docker images are referenced by the image name. Docker image name is made of 3 parts: repository name, image name and an image tag. You can store these images locally on your machine, but in order to share them you will probably use a Docker registry. --- ## Docker Registry - Place to store your Docker images - Public and private repositories - Docker Hub (https://hub.docker.com) - Every cloud provider has its own - You can also store images locally, on your Docker host ??? Docker registry is a place where you can upload and store your Docker images. There are both private and public repositories and every cloud provider has it's own managed registry that you can use. --- class:pic 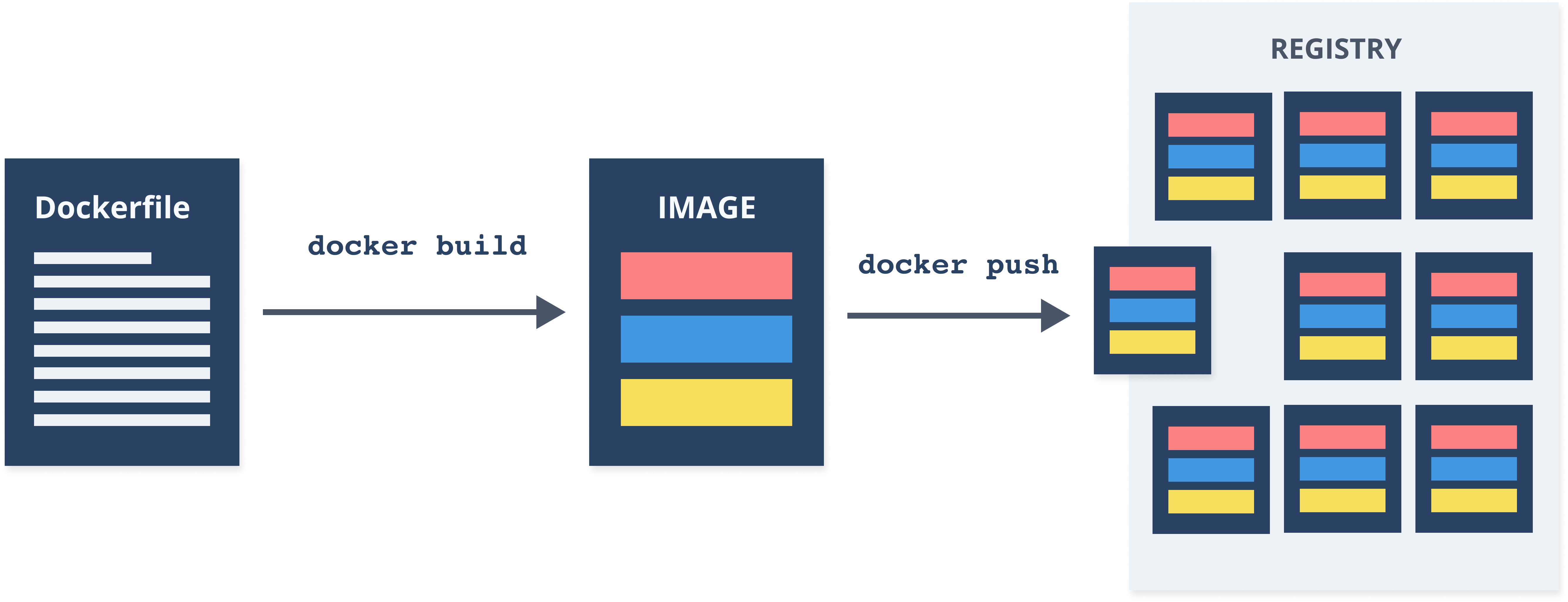 ??? Let’s look at some common scenarios with Docker The first one is a docker build and docker push. The Docker build takes a Dockerfile, a build context (a folder with your code or files) and an image name and it builds a Docker image. Once you have that Docker image, you can use the `docker push` to push or upload that image to a Docker registry. --- class:pic 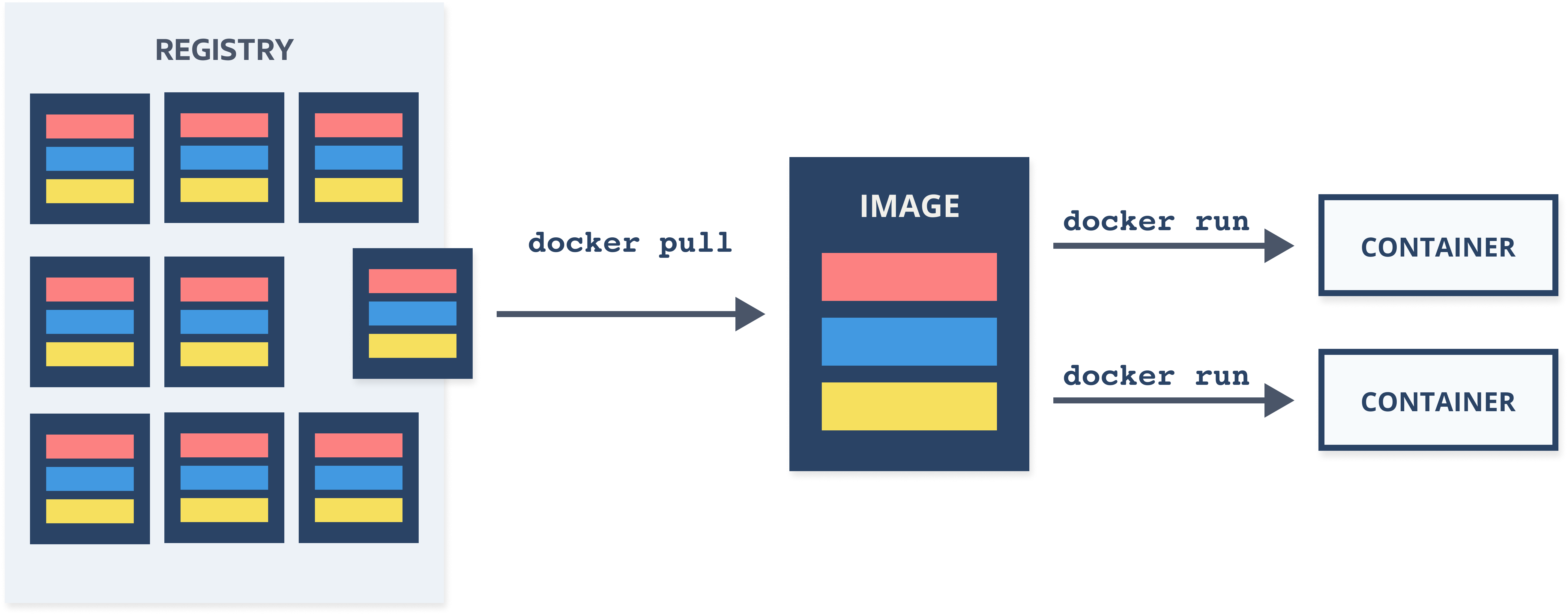 ??? Once you've pushed the image, you can use the docker pull command. The pull command will go to the Docker registry and download or pull the image to your local machine. Finally, you can use the docker run command to create a container from that image. Note that you don't need to pull the image first to run it, you can just directly run the container and docker will automatically download the image to your machine. The Docker run command also has a lot of options and parameters you can pass-in to control how the container is run. For example, you can pass environment variables to the container, you can share your local folder inside the container, define the ports from to expose to your machine and bunch of other things. --- name: kubernetes class: pic, center,middle  --- ## Container Orchestration - Provision and deploy containers onto nodes - Resource management/scheduling containers - Health monitoring - Scaling - Connect to networking - Internal load balancing ??? Container orchestration talks about managing the lifecycles of containers. It help you with: - provisioning and deploying containers based on resources - doing health monitoring on containers - load balancing and service discovery - allocating resources - scale the containers up and down --- ## Kubernetes Overview - Most popular choice for cluster management and scheduling container-centric workloads - Open source project for running and managing containers - K8S = K.highlight[ubernete]S **Definitions** _Portable, extensible, open-source platform for managing containerized workloads and services_ _Container-orchestration system for automating application deployment, scaling, and management_ .footnote.small[*https://kubernetes.io*] ??? Kubernetes is most popular choice for cluster management and container orchestration and you can use it to run your containers, do zero-downtime deployments and bunch of other stuff. K8S = numeronym --- class:pic ## Kubernetes Architecture 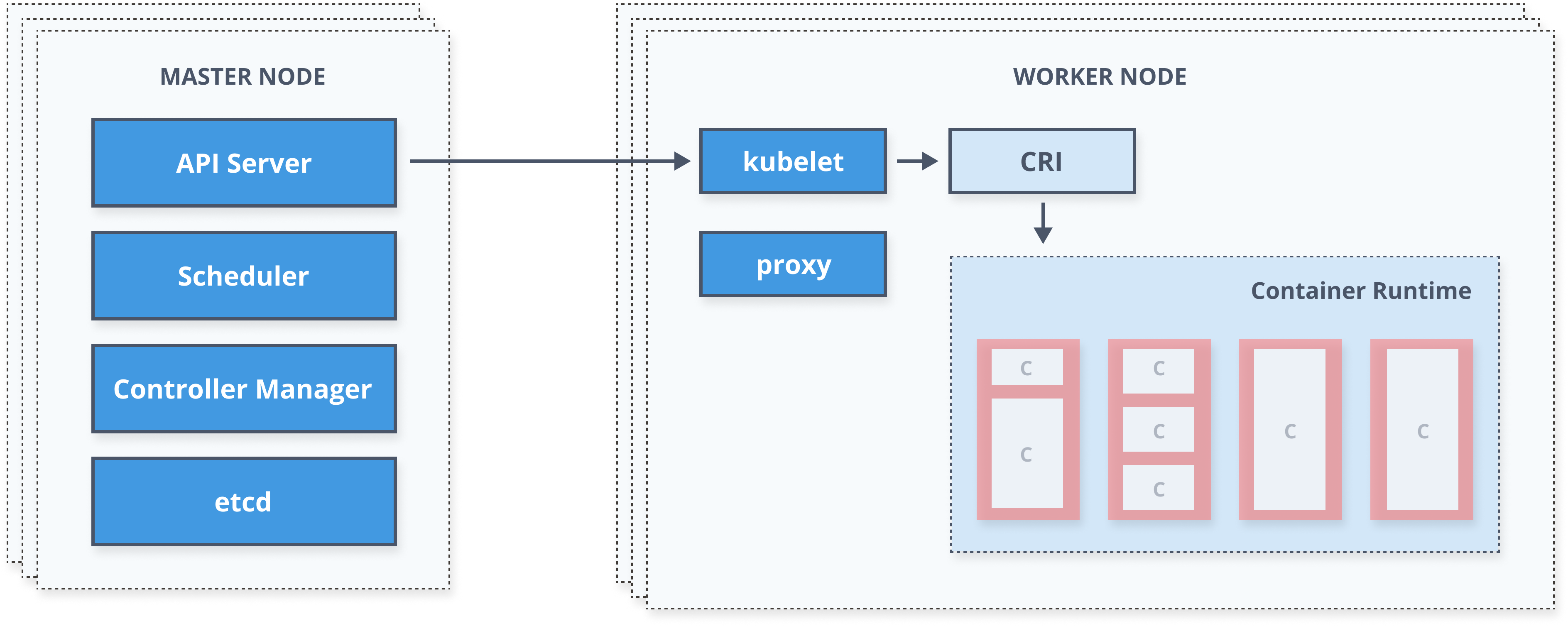 ??? A Kubernetes cluster is a set of physical or virtual machines and other infrastructure resources that are needed to run your application. Each machine in a cluster is called a **node**. There are two types of nodes: - Master node: this node hosts the k8s control plane and manages the cluster - Worker node: runs your containerized applications --- class: pic  ??? **API server** One of the main components that runs on a Master node is called the API server. The API server is an endpoint that Kubernetes CLI uses for example to create the resources and to manage the cluster. **Scheduler** The scheduler component works together with the API server to schedule the applications to the worker nodes. It has the information about available resources on the nodes and the resources requested by applications. Using this information it decides on which worker node will your applications end up on. **Controller manager** Watches the state of the cluster and tries to reconcile the current state of the cluster with the desired state. It runs multiple controllers that are responsible for nodes, replication, endpoints, service accounts etc. **etcd** Etcd is a distributed key-value store and this is where the state of the cluster and API objects are stored in. --- class: pic  ??? **Kubelet** Service that runs on each node and manages the containers. It ensures containers are running and healthy and to connect to the control plane. It talks to the API server and only manages the resources on its node. When a new node comes up, kubelet introduces itself and provides the resources ("I have X CPU and Y memory") and asks if there are any containers that need to be run. Think of a kubelet as a node manager. **CRI/Container runtime** kubelet uses a container runtime interface (CRI) to talk to the container runtime that's responsbile for working with containers. In addition to Docker, Kubernetes also supports other container runtimes, such as containerd or cri-o **Pods/Container** The containers are running inside pods (the red rectangles) - pods are the smallest deployable units that can be created, schedule and managed on a Kubernetes cluster. It's a logical collection of containers that make up your app. Containers inside the same pod share the network and storage space and define how containers should be run. **Proxy** Each worker node also has a proxy that acks as a network proxy and a load balancer for services running on the work node. Client requests coming through external load balancerrs are redirected to containers running in pod through this proxy --- ## Kubernetes Resources - Multiple resources defined in the Kubernetes API - namespaces - pods - services - secrets - ... - Custom resources as well! - CRD (.highlight[C]ustom .highlight[R]esource .highlight[D]efinition) ??? The kubernetes APIs defines a lot of objects that are called resources different properties and fields Of course, you can define your own, custom resources as well `kubectl api-resources` – lists all resources known by the api servers --- class: pic  ??? Pods are the most common resource in Kubernetes. They are a collection of containers that share the namespace, network and volumes. Any containers inside a pod get scaled together, as one unit. Each pod also gets a unique IP address – containers within a pod can communication between each other by simply using localhost. --- ## Pods - Smallest deployable/manageable/scalable unit - Logic grouping of containers - All running on the same node - Share namespace, network, and volumes - Has a unique IP - Controlled by a ReplicaSet ??? Even though pods can be created directly, you will probably never do that. Pods are designed to be disposable, so if you create an individual pod, you schedule it to run on a node in the cluster. If the pod crashes or gets deleted, it will be gone and it won’t restart itself. This is probably the opposite of what we want – if you have your service running in a pod, you’d want it to get restarted and rescheduled automatically if something bad happens. To do that, you need to use a controller – this controller will manage the pods lifecycle and ensure that it gets rescheduled and restarted if something goes bad. --- ## Pods ``` line-numbers apiVersion: v1 kind: Pod metadata: name: myapp-pod labels: app: myapp spec: containers: - name: myapp-container image: busybox command: ['sh', '-c', 'echo Hello Minsk! && sleep 3600'] ``` ??? --- ## ReplicaSet - Ensures specified number of pod replicas is running - Creates and deletes pods as needed - Selector + Pod template + Replica count ??? The purpose of a replicaset is to maintain multiple copies of a pod. It's used to guarantee that a specified number of identical pods is running at all times. The resource needs selector to know how to identify pods, a number of replicas - number of copies of pods it should be maintaining and a pod template that specifies the information about each pod. The replicaset controller then uses the current state (let's say you don't have any pods running) and the desired state (let's say you want 5 replicas) and tries to create the pods to meet the desired state. Once the pods are created, it monitors them. For example, if you delete one pod, it will automatically re-create it. --- ``` line-numbers apiVersion: apps/v1 kind: ReplicaSet metadata: name: myapp labels: app: myapp spec: replicas: 5 selector: matchLabels: app: myapp template: metadata: labels: app: myapp spec: containers: - name: myapp-container image: busybox command: ['sh', '-c', 'echo Hello Minsk! && sleep 3600'] ``` ??? line 8,9: replicas to define how many instances of the pod we want, and the match lables to tell replicaset how to find the pods line 12: Pod template with labels and spec that has the containers --- class: center, middle # Demo ### Pods and ReplicaSets --- ## Deployments - Describes desired state - Manages updates - Controlled roll-out from actual state to the desired state ??? With replicaset we can ensure that we have a certain number of replicas running. Using a deployment, we can then manage replicasets and provide updates to pods for example. The deployment is there to allow us do controlled updates – so if we want to change the image (use a different version etc.) we can use the deployment to do that. If you only have a replicaset, we would need create a new replicaset with a new image version, then delete the old replicaset. All this functionality can be wrapped inside a deployment --- ``` line-numbers apiVersion: apps/v1 kind: Deployment metadata: name: myapp labels: app: myapp spec: replicas: 5 selector: matchLabels: app: myapp template: metadata: labels: app: myapp spec: containers: - name: myapp-container image: busybox command: ['sh', '-c', 'echo Hello Minsk! && sleep 3600'] ``` ??? Deployment is a resource used for describing how to create and update your application. Once you create a deployment, the pods will get schedule onto nodes in your cluster. If any of those pods crashes, the controller will automatically reschedule and restart the pod. Similarly if you change the number of pod replicas (or copies), it will make sure to scale the pods up or down accordingly. Just like with other resources, each deployment has a name, set of labels as well as a template that describes the pods and containers. --- class: pic  ??? As mentioned earlier, Kubernetes Pods are mortal and once they die, they are gone and won’t come back. So we start with a deployment and deployment will make sure there’s 1 replica of our pod running. This pod also gets a unique IP address. --- class: pic  ??? If we try to make requests to that IP address, we can and everything works fine…. --- class: pic  ??? until that pod dies. --- class: pic  ??? Since we are using a deployment, a new pod will be started and it will have unique IP again (not the same as the previous one, but different) This is a problem. It’s apparent that we can’t rely on pods IP address. This is where Kubernetes services come into play! --- class: pic  ??? Service is an abstraction that defines a logical set of pods and give us a way to reliably reach the pods. Service keeps a list of endpoints (pod IPs) and directs requests to them. These endpoints are kept up to date, so anytime a new pod starts or one crashes, the endpoints list gets updated. --- ## Services - Define a logical set of pods - Pods are determined using labels (selector) - Reliable, fixed IP address - Automatic DNS entries - E.g. `hello-web.default` --- ``` line-numbers kind: Service apiVersion: v1 metadata: name: myapp labels: app: myapp spec: selector: app: myapp ports: - port: 80 name: http targetPort: 3000 ``` ??? The logical set of pods or endpoints is defined by a label selector. In this example, we have a label selector on line 9 `app: myapp` and this means that any pod with that label will be included in the list of endpoints for this service. Notice we are also defining a port – this is the port service can be accessed on as well as the port on the Pod. There’s a key call `targetPort` (on line 13) which can be used to define different ports to reach on the pods. Whenever a new service gets created, a DNS server inside the cluster creates a set of DNS records. For example, for the `myapp` service, the DNS entry called `myapp` and `myapp.default` get created. First one can be used to access the service from within the same namespace, while the second one can be used to access a service from another namespace. A good practice is to always use the full name for the service. --- ## Services **ClusterIP** - Service is exposed on a cluster-internal iP (default) **NodePort** - Uses the same static port on each cluster node to expose the service **LoadBalancer** - Uses cloud providers' load balancer to expose the service **ExternalName** - Maps the service to a DNS name ??? For some pods you probably want to expose some services outside of your cluster. There are multiple different service types you can use: ClusterIP : default type, service is exposed only internally, inside the cluster; it gets an internal IP NodePort: exposes the service on the same static port on each cluster node. The service is then accessible from outside of the cluster using the public node IP address and the NodePort. LoadBalancer: exposes the service through the cloud providers load balancer (assuming cloud provider supports it) ExternalName: map the service name to an actual DNS name How do you expose multiple services to the outside world then? Do you create multiple loadbalancers? That would be too costly and not efficient. Kubernetes has another resource that can help with this – the ingress resource! --- ## Ingress - Exposes HTTP/HTTPS routes from outside the cluster to services within the cluster - Ingress controller uses a load balancer to handle the traffic (based on the ingress rules) - Fanout and name based virtual hosting support: - blog.example.com -> blog-service.default - chat.example.com -> chat-service.default - ??? The ingress resource helps with exposing routes from outside the cluster to the services running inside the cluster. The resource has a set of rules that decide where traffic gets routed to. For example, you can use an ingress resource and controller to route anyone visting www.myhelloweb.com to a service running within your cluster. You can also define ingress rules to do a simple fanout -- using the same host, you can redirect traffic to different services within the cluster. Finally, you can secure an ingress by specifying a Kubernetes secret that contains a TLS private key and certificate. --- ```line-numbers apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: ingress-example annotations: nginx.ingress.kubernetes.io/rewrite-target: / spec: rules: - host: blog.example.com http: paths: - path: / backend: serviceName: blog-service servicePort: 3000 - path: /api backend: serviceName: blog-api servicePort: 8080 ``` ??? --- ## Config Maps - Stores configuration values (key-value pairs) - Values consumed in pods as: - environment variables - files - Helps separating app code from configuration - Needs to exist before they are consumed by pods (unless marked as optional) - Need to be in the same namespace as pods --- ``` line-numbers apiVersion: v1 kind: ConfigMap metadata: name: hello-kube-config namespace: default data: count: 1 hello: world ``` --- ## Secrets - For storing and managing small amount of sensitive data (passwords, tokens, keys) - Referenced as files in a volume, mounted from a secret - Base64 encoded - Types: generic, Docker registry, TLS --- ## Namespaces - Provides unique scope for resources - `my-namespace.my-service` - `another-namespace.my-service` - (Most) Kubernetes resources live inside a namespace - Can't be nested ??? You can use Kubernetes namespaces to divide the cluster between multiple users and organize and logically group resources together. For example: I could create multiple namespaces for different users or per projects or for different portions of a project and so on. If doing that you should also make sure to set the resource quotas and security policies – you probably don’t want one user or project to take up all the resources or have access to resources running in other namespaces. Initially, there are three namespaces that get created. Kube-system namespace for system resources, you usually don’t deploy anything into this namespaces. Similarly with the kube-public namespace – it’s used for cluster usage and in case you want to make resource visible and readable publicly. The namespace we will be using is called ‘default’. Any resource you create gets created in the default namespace (assuming you didn’t explicitly provide a namespace). Namespaces also provide you a unique scope where you can deploy your resources in. Resources inside the namespace need to be unique, but they don’t have to be unique across namespaces; you can have a resource called “my-service” in multiple namespaces, however you can’t have two resources with the same name in one namespace. --- class: middle,center # Exercises - Kubernetes ### `./kubernetes` .big[https://github.com/peterj/jfuture] --- name: service-mesh-overview class: center, middle # Service Mesh --- class: center, middle ### Dedicated infrastructure layer to .highlight[connect], .highlight[manage], and .highlight[secure] workloads by managing the communication between them ??? - service mesh is all about communication between services --- class: pic  ??? Instead of implementing common network and communication code inside each service, why not push it out of the service and have the service mesh or the proxy handle it? This allows you, the developer to focus on the business logic and not on implementing network related code. Similarly, if you're the operator, you have the ability of defining network behavior through these proxies. --- ## Service Mesh - Architecture **Data plane (proxies)** - Run next to each service instance (or one per host) - Istio uses Envoy proxy - Intercept all incoming/outgoing requests (`iptables`) - Configure on how to handle traffic - Emits metric **Control plane** - Validates rules - Translates high-level rules to proxy configuration - Updates the proxies/configuration - Collects metrics from proxies ??? At a high level, any service mesh has at least two parts: the data plane and the control plane. A data plane is the collection of all proxies that run next to each service. These proxies intercept any traffic coming to the service or leaving the service. They are driven by a configuration and have the ability to automatically reload the configuration when it changes. Additionaly, they can also emit metrics about the traffic that passes through them. The job of a control plane is as the name suggest to 'control' the data plane or the proxies in the data plane. Control plane is usually the entry point or the endpoint that developers can use to control the service mesh. The components inside the control plane take the high-level rules (traffic rules, configuration, or policies), they can validate them and then translate them to the proxy-specific configuration and push them to all the proxies. There's other components that deal with metrics or security that are usually run as part of the control plane as well. Some people also talk about a management plane whos purpose would be to manage multiple meshes across multiple clusters. --- ## Service Mesh - Features **Connect** - Layer 7 routing and traffic management - %-based traffic split (URIs, header, scheme, method, ...) - Circuit breakers, timeouts and retries **Manage** - Telemetry (proxies collect metrics automatically) - Visibility into service communication without code changes **Secure** - Secure communication between services (mutual TLS) - Identity + cert for each service ??? Layer7 routing -- make decisions based on the content of the message - URL, cookies, headers, method, etc. - Tools: Grafana, Jaeger, Kiali - Cert lifecycle managed by the proxy - Access control (namespace, service, method level) --- class: pic  --- name: traffic-management class: center, middle # Traffic Management --- class: pic  ??? Here are some of the things we need to know: Each pod has an injected Envoy proxy next to it Envoy proxy intercepts and forwards all traffic between the caller and the service All rules come from the Pilot and are pushed to the Envoy proxies, and proxies reconfigure themselves automatically We write the rules using YAML and send them to the cluster --- class: pic  ??? Pilot maintains a platform independent abstract model of services in the mesh. It uses platform adapters to translate and populate it’s model. For example, the Kubernetes platform adapter monitors pods, ingresses and other traffic related resources that store traffic management rules and translates that data into abstract representation. The envoy API then uses this abstract model to create Envoy specific configuration that gets pushed to all the proxies running in the mesh. Upon a change in their configuration, the proxies reconfigure themselves automatically. --- class: pic  ??? Using this design, the callers of the service have no clue about different versions of the destination service. Service A does not know there are two version of service B. it just calls Service B and the proxies decide (based on the routing rules) how and where to route the traffic. --- ## Service Mesh - Istio **Traffic Management Resources** - Gateway - VirtualService - DestinationRule - ServiceEntry - Sidecar ??? There are 4 Istio resources involved in traffic management in Istio. Using these rules you can tell Istio how to deal with the traffic. --- ## Service Mesh - Virtual Service ```yaml apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: service-b spec: hosts: - service-b.default.svc.cluster.local http: - route: - destination: * host: service-b * subset: v1 * weight: 98 - destination: host: service-b subset: v2 weight: 2 ``` ??? Virtual service defines the rules that control how requests for a service are routed within an Istio service mesh. You can use a Virtualservice to route requests to different versions of a service or to a completely different service. You can do the routing based on the request source and destination, http paths and header fields, and weights associated with individual service versions. --- ## Service Mesh - Destination Rule ```yaml apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: service-b spec: host: service-b.default.svc.cluster.local * subsets: - name: v1 labels: version: v1 - name: v2 labels: version: v2 * trafficPolicy: tls: mode: ISTIO_MUTUAL ``` ??? Destination rule configures set of policies that get applied to a request after virtual service does the routing. For example, we can apply the TLS policy as well as define the subsets. --- class: pic  ??? Let’s look at an example We have 4 pods labelled app=hello and version=v1 and version=v2. These pods are created by their own deployment- v1 deployment and v2 deployment. Lastly, we have a service-b that uses ‘app=hello’ as a selector. --- class: pic  ??? If we make a request to the service-b, we will either get a response from a v1 pod or from a v2 pod. Because the app=hello selector returns all pods. --- ## Destination rule ```line-numbers apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: service-b spec: host: service-b.default.svc.cluster.local subsets: * - name: v1 * labels: * version: v1 * - name: v2 * labels: * version: v2 ``` ??? With the subsets we can say that we want to apply additional labels to the service selector, depending on which subset we are routing to. We can define a subset called v1 and v2 that apply an additional label (e.g. version=v1) when traffic hits the service. --- ## Virtual service ```line-numbers ... http: - route: - destination: * host: service-b * subset: v1 * weight: 30 ``` ??? Once the traffic gets routed to the destination that we defined in the virtual service, we also specify the subset of the service we want to route the traffic to. --- class:pic  ??? so, the routing occurs in the virtualservice we want to route the traffic to service-b and subset v1; this means that in addition to applying the app=hello label, the version=v1 label is going to be applied as well and we will only get responses back from the pods labelled with v1 version. --- class:pic  ??? Similarly, when the traffic gets routed to subset V2, the additional label will get applied and the traffic will get routed to the pods that are labelled with v2. --- class:pic  ??? --- ## Service Mesh - Service Entry ```yaml apiVersion: networking.istio.io/v1alpha3 kind: ServiceEntry metadata: name: movie-db spec: hosts: * - api.themoviedb.org ports: * - number: 443 name: https protocol: HTTPS * resolution: DNS * location: MESH_EXTERNAL ``` ??? Service entry is used to enable requests to service outside of the mesh. --- ## Service Mesh - Gateway ```yaml apiVersion: networking.istio.io/v1alpha3 kind: Gateway metadata: name: gateway spec: selector: * istio: ingressgateway servers: - port: * number: 80 name: http protocol: HTTP hosts: * - "hello.example.com" ``` ??? Gateway – is used for defining a load balancer that operates at the edge of the mesh for ingress and egress traffic. You can use this resource to expose the services to the outside world. You can also attach the gateways to a VirtualSErvice (if you want to make it publicly accessible). Istio also installs an ingress and egress gateway that acts as a controller for the gateway resource (similar to the controller for ingress resource in kubernetes) --- class:pic  ??? Let's look at an example. We have Kubernetes cluster with a bunch of service running inside and we want to make `service-a` accessible from the public internet. --- class:pic  ??? As part of Istio, an ingress gateway gets installed (Envoy proxy) and it is exposed on a an external IP address. If using Docker for mac/windows, this will be localhost, however if you are using a cloud-hosted Kubernetes, this will be an actual Load balancer that gets provisioned at the cloud provider and it gives you an external IP address. --- class:pic  ??? Once you have the external IP address you can create a Gateway resource where you define the port and the hosts where you want gateway to be accessible on. Practically speaking, you would enter your domain or subdomain name that you want to use and you register at your domain registrar. If that set up, you can go to the DNS settings on your domain registrar and enter that external IP address as an A record and set up a CNAME record for your domain as well. With this you are saying that whenever someone types in `www.service-a.com` you want it to resolve to that IP address. --- class:pic  ??? Finally you need to tell that ingress gateway to which service inside Kubernetes you to route the traffic to. Otherwise the traffic will just go nowhere. The way tou set that up is to attach the gateway to the virtual service under the gateway field. Attaching the gateway resource to a virtual service like that will make that virtual service accessing from the gateway. --- ## Service Mesh - Sidecar ```yaml apiVersion: networking.istio.io/v1alpha3 kind: Sidecar metadata: name: default namespace: prod-us-west-1 spec: egress: - hosts: - 'prod-us-west-1/*' - 'prod-apis/*' - 'istio-system/*' ``` ??? Sidecar resource is the recent addition to Istio. It is used to control the configuration of the sidecar proxy – specifically the inbound and outbound communication. By default, the proxies in the mesh are configured in such as way that they accept any traffic and can be reach from any service on all ports. With the sidecar resource, you can control and fine tune the set of ports, protocols that proxy accepts when it forwards the traffic to your service. Additionally, you can also restrict the service proxy can reach. For example, with yaml snippet we are declaring a sidecar resource in the prod-us-west-1 namespace that configures all Envoy proxies in hat namespace and allows egress (outgoing) traffic to services running in the prod-us-west-1, prod-apis and istio-system namespaces. Similarly, you could also define the ingress portion and control which traffic can get in to the services. --- ## Service Mesh - Traffic Management - Define subsets in DestinationRule - Define route rules in VirtualService - Define one or more destinations with weights ??? So how can we split the traffic to multiple versions of the same service? As a first step, we need to determine the subsets or the way we want to split the traffic. Are we splitting it based on the version? Or based on the environment or any other label or key/value pair? Once we have the subsets defined, we can create a route rule in Virtual service. Under each route rule, we can have one or more destinations that the traffic gets routed to. These destinations will use the subsets we defined in the destination rule. Additionally, we need to set the weights to all destinations to define how the traffic should be split. --- class: center, middle # Demo ### Istio Traffic Routing --- class: middle,center # Exercises - Traffic Management ### `./istio/traffic` .big[https://github.com/peterj/jfuture] --- name: resiliency class: middle, center # Service Resiliency --- class: middle, center # Resiliency ### Ability to .highlight[recover from failures] and .highlight[continue to function] ??? what is resiliency? It’s not about avoiding failures, it’s responding to failures in such a way that there’s no downtime or data loss. --- class: middle, center ### Return the service to a .highlight[fully functioning state] after failure ??? A simple goal of resiliency is to return the service to a fully functioning state after a failure occurs --- ## Resiliency **High availability** - Healthy - No significant downtime - Responsive - Meeting SLAs **Disaster recovery** - Design can't handle the impact of failures - Data backup & archiving ??? There are two aspects to the service resiliency One is high availability which basically says that : Service is running in a healthy state There’s no significant downtime Service is responsive and users can interact with it Service is meeting SLAs etc. Second aspect is disaster recovery Disaster recovery is all about how to recover from rare but major incidents (involves data backup, archiving, etc.) We can also say that disaster recovery starts when high availability design can’t handle the impact of faults --- ## Resiliency Strategies - Load Balancing - Timeouts and retries - Circuit breakers and bulkhead pattern - Data replication - Graceful degradation - Rate limiting ??? Next I am going to talk about some strategies that can help you with service resiliency Load balancing: any service should be able to scale out by adding more instances. There are different Load balancing algorithms that can help with achieving better resiliency: e.g. round robin, random, least conn Timeouts & Retries: Crucial element in making services available; network introduces a lot of unpredictable behavior, one of them being latency ,so how long do you wait for the service response? Is something wrong or is service just slow? Do you just wait? Waiting == bad - there’s usually a customer at the other end that’s waiting for something; also waiting uses resources and might cause other services to wait, leading to potential cascading failures Solution: Always have timeouts! Even with timeouts in place, network could be experiencing transient failures and if only we retried one more time, the call might have succeeded. Guideline: make at least a couple of attempts before calling it quits and giving up on the service Some examples of retries: hardcoded delay between each retry, exponential back-off Circuit breakers & bulkhead pattern - we mentioned the cascading failures that can occur in systems; circuit breaker pattern is what you can use to prevent additional strain to the system and prevent cascading failures. the way circuit breaker works is that it encapsulates the functionality or services that needs to be protected. You need to configure a threshold in your circuit breaker that will cause it to trip. For example: 10 consecutive failures in 5 seconds, or more than 2 connections, etc. Once those values are exceeded, circuit breaker trips and it removes the failing service from the load balancing pool for a predefined amount of time (e.g. a minute, 5 minutes, ...). -Bulkhead pattern: isolate critical resources, so failures in one subsystem can’t cascade and cause failures in other parts of the application Data replication: General strategy for handling non-transient failures in data store; many storage technologies have the replication built in; Degrade gracefully: If one service fails, the whole system should continue working; for example, you can provide an acceptable user experience even without all services up and running Use cached data, put items on the queue, show the error message, etc. Rate limiting: - Make sure you are rate limiting the requests, so no one user can create excessive load --- ## Service Mesh - Timeouts ```yaml apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: service-b spec: hosts: - service-b.default.svc.cluster.local http: - route: - destination: host: service-b subset: v1 * timeout: 5s ``` ??? By default any timeouts for HTTP requests in Istio are disabled, but we can set or enable them by adding a timeout field to the Virtual Service. You can also dynamically overwrite the timeout from your service using the above header value --- ## Service Mesh - Retries ```yaml apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: service-b spec: hosts: - service-b.default.svc.cluster.local http: - route: - destination: host: service-b subset: v1 * retries: * attempts: 3 * perTryTimeout: 3s * retryOn: gateway-error,connect-failure ``` ??? Similarly, we can define the retries in the virtual service. We define the number of retries and the amount of time to wait between each try --- this is so you don’t put unnecessary strain on the service and to minimize the impact on an overloaded service You can also configure the types of HTTP codes to retry on, for example gateway error, connection failure, reset, 500. Additionally, you can also define the status codes on which to retry using a header. --- ## Service Mesh - Circuit Breakers ```yaml apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: service-b spec: host: service-b.default.svc.cluster.local * trafficPolicy: * tcp: * maxConnections: 1 * http: * http1MaxPendingRequests: 1 * maxRequestsPerConnection: 1 * outlierDetection: * consecutiveErrors: 1 * interval: 1s * baseEjectionTime: 3m * maxEjectionPercent: 100 ``` ??? Circuit breaker settings can be applied on the destination rule for the service. Compared to retries and timeouts there are way more knobs you can adjust. First thing that needs to be defined is the connection pool settings. You can apply them both at the TCP level and at the HTTP level. For TCP, the following fields can be set: max connections Connection timeout TCP keep alive settings (number of probes to send before deciding connection is dead, time and interval) For HTTP: http1MaxPendingRequests/http2MaxRequests -> maximum number of requests (Default is 1024) maxRequestsPerConnection -> max number of requests per connection maxRetries -> max number of retries that can be outstanding idleTimeout -> period in which there are no active requests. When idle timeout is reached, the connection is closed With these values set, you are limiting the connection pool and requests that will be made to the service; if we go over these values we are short-circuiting the circuit breaker. For example, if we’d make more than 1 connection to the service, the circuit break would short circuit calls that didn’t match the config settings. What about if nodes go down in the cluster? Or some of our pods keep restarting? This is where the outlier detection comes into play. The outlier detection can detect when hosts are not reliable and can eject them for a period of time. So if we think about a Kubernetes service that load balances between 10 pods – if some of those pods are unhealthy and the outlier detection detects that, it will exclude or eject those pods from the load balancing pool. Let’s look at the settings: consecutiveErrors number of errors before a host is ejected from the pool (default value is 5) – 502, 503 or 504 qualify as errors; for TCP, timeouts and connection errors qualify as errors Interval period between host scanning; for example, the 10 second default value means that the upstream hosts will be scanned every 10 seconds and analyzed for failures baseEjectionTime this value represents minimum ejection duration (default is 30 seconds) maxEjectionPercent max % of hosts in the pool that can be ejected – default is 10% -- this means if more than 10% of the hosts are failing, only 10% will be ejected. minHealthPercent with this value you can control if outlier detection is enabled or not. For example: if you set the minHealthPercent to 50% and the number of unhealthy hosts drops below 50%, the outlier detection is disabled and in that case proxy will load balance across all hosts in the pool, regardless if they are healthy or not --- ## Service Mesh - Delays ```yaml apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: service-b spec: hosts: - service-b.default.svc.cluster.local http: - route: - destination: host: service-b subset: v1 * fault: * delay: * percentage: 50 * fixedDelay: 2s ``` ??? For example, you can inject a fixed delay for a certain percentage of requests coming to the service. With this you can simulate latency and test how your services behave. In the example above, we are saying that we want 50% percent of incoming requests to be delayed by 2 seconds. --- ## Service Mesh - Aborts ```yaml apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: service-b spec: hosts: - service-b.default.svc.cluster.local http: - route: - destination: host: service-b subset: v1 * fault: * abort: * percentage: 50 * httpStatus: 404 ``` ??? Similarly as with the delays, you can also inject aborts to your services. This example is saying that for 20% of the requests, the service will return an HTTP status of 404. The best thing about all this: you can combine aborts with delays. And with the routing policies and with conditions. If you think about it, this can be an extremely powerful tool that helps you with testing your services and making them more resilient. --- class: center, middle # Demo ### Service Resiliency --- class: middle,center # Exercises - Resiliency ### `./istio/resiliency` .big[https://github.com/peterj/jfuture] --- name: security class: middle, center # Security --- background-image: url(./images/access-control-lock.jpeg) background-size: cover ??? When talking about security, we need to start with the access control systems. --- ## Access Control ## .center[Can a .highlight[principal] perform an .highlight[action] on an .highlight[object]?] ??? The question access control systems try to answer is: can some principal perform an action on an object? <hr/> -- <br/> .center[ ### .highlight[Principal] = user ### .highlight[Action] = delete ### .highlight[Object] = file ] ??? An example would be: can a user delete a file, or read or execute a script. Or if I put it in Istio/Kubernetes/cloud-native/microservices terms: can Service A perform an action on Service B When talking about access control, we need both authentication AND authorization. --- ## Authentication (authn) - Verify credential is valid/authentic - Istio: X.509 certificates - Identity encoded in certificate ??? Authentication is about the principal and is the act of taking a credential and making sure that it's valid and authentic. The credential in Istios case is a X.509 certificate and it has an encoded identity in the certificate. Once an authentication is performed, we are talking about authenticated principal. --- ## Authorization (authz) - Is principal allowed to perform an action on an object? - Istio: RBAC policies - Role-based access control ??? What authorization tries to do is to answer the question if a principal is allowed to perform the action on the object. You can be authenticated, however you still might not be allowed to perform an action. Authorization of service-to-service communication in Istio is configured using RBAC (role based access control) policies. --- class: center, middle ## .highlight[Authentication] and .highlight[authorization] work together ??? We need both authorization and authentication, otherwise have one without another is useless. If you only authenticate the user without authorization, they can do whatever they want - perform any action on any objects. Similarly, if you only authorize the requests, a user can pretend to be someone else and again perform thwe actions. --- ## Identity - SPIFFE - SPIFFE (Secure Production Identity Framework for Everyone) - Specially formed X.509 certificate with an ID (e.g. `spiffe://cluster.local/ns/default/sa/default`) - Kubernetes: service account is used .footnote[https://spiffe.io/] ??? The next thing that we need is tofigure out what is the identity in Istio. Identity is quite important as all functions inside the mesh rely on understanding how to identify the services. SPIFFE provides a secure identity using a specially formed X.509 certificate. Istio implements this specification to issue the identities. It creates the X.509 certificates that have the subject alternative name (SAN) set to a URI that describes the service. In Kubernetes case, Istio will use pods' service account as its identity and encode it into a URI. This means that if you haven't explicitly provided a service account you want your pod to use, it will use a default service account from the namespace. --- ## Identity - SPIFFE Concepts: - Identity (URI) - `spiffe://cluster.local/ns/default/sa/default` - Encoding of identity into SVID (SPIFFE Verifiable Identity Document) - X.509 and Subject Alternate Name (SAN) field - API for issuing and retrieving SVIDs ??? Citadel is the implementation of the SPIFFE specification that can bootstrap and issue identities. There are three concepts that SPIFFE specification describes: - identity that's used by services to communicate - this is the URI which uses Kubernetes' service account - standard encoding of the identity into the SVID - SVID is a X.509 certificate that has the identity encoded in the SAN field - an API for issuing and retrieving SVIDs - Istio implements certificate provisioning using a custom protocol --- ## Key management - Citadel - Certificate authority (CA) - Signs certificate requests that create X.509 certificates - Citadel (node) agents (SDS - secret discovery service) - Broker between Citadel and Envoy proxies - Envoy ??? The key management achitecture has three components - their job is to issue and rotate SVIDs. Citadel acts as a certificate authority and issues identities to workloads. It signs the certificate requests that form X.509 SVID. It accepts the requests for identity, authenticates, authorizes them and issues a certificate. Citadel Node agent is deployed on each node in the cluster and it acts as broker between the Citadel and sidecars on the node. Envoy talks to the citadel agent to retrieve the identity and presents it to other services at runtime. Note that by default the Secret discovery service is not deployed. You need to explicity enable it. Since we aren't using SDS, the certificates are distributed using kubernetes secrets instead. Using a node agent is a better design - as the private key never leaves the node - it's only in the Citadel agent and the Envoy. You also don't need the secret volume mount aand finally Envoy can dynamically renew the key through the SDS API, so no need to restart Envoy proxies anymore. --- ## Mutual TLS (mTLS) **Flow** 1. Traffic from client gets routed to the client side proxy 2. Client side proxy starts mTLS handshake - Secure naming check: verify service account in the cert can run the target service 3. Client and server side proxies establish mTLS connection 4. Server side proxy forwards traffic to the server service ??? Let's talk about how are these certificates then used practically to identify the parties that communicate. First thing that comes to your mind when talking about TLS is HTTPS. You open a browser to go to https://hello.com - the borwser fires off an HTTPS request and waits for the service. When the browser tries to connect, the server presents the certificate with an identity (hello.com) that's signed by something browser trusts. The browser then validates the certificate, authenticates the identity of it and allows the connection to be establish. Finally, a set of keys are generated for the connection to enable encryption. An real-world example here would be me presenting a passport to a customs officer - passport has my identity and it's signed by an authority that the customs officer trusts. Now mTLS is where both client and the server present the certificates. This allows both client to verify the server as well as server to verify the client. If I go back to the customs officer example, it's me showing them my passport, but also them showing me their identification as well. Traffic in between services gets routed through the Envoy proxies. The traffic leaving the service goes to the client sidecar proxy. The proxy then starts the mTLS handshake with the server side Envoy proxy. During this handshake, the proxy does a secure naming check to make sure that the service account in the server certificate is authorized to run the target service. The proxies establish the mTLS connection and finally the server side proxy can forward the traffic to the service. --- ## Istio Auth Policies Authn policy: - Controls how proxies communicate with one another - mTLS on/off Authz policy: - Requires authn - Configures which identities are allowed to communicate ??? Authentication and authorization policy in Istio is split into two sets of configuration. The authentication policy controls how the proxies within the service mesh communication with each other - do they require certificates or not The second set is authorization - this one requires authentication polciy and then configures with services or identities are allowed to comunicate --- ## Configuring mTLS/JWT - Policy resource (`authentication.istio.io/v1alpha1.Policy`) - Scope: - Mesh < namespace < service - Also supports JWT ??? The main resource used for configuring the mTLS is called Policy. It allows you to require strict mTLS between services, make it optional - meaning that you can either use plaintext or TLS or disable it. All this on either whole service mesh level(i.e. everything within the mesh or cluster), namespace or for each service separately. Depending on which policies are set, the namespace policy takes precedence over the mesh policy, while the per service policy still has a higher precedence. Having the ability to make mTLS optional makes it easier to gradually enable mTLS for existing service you have. Istio also supports doing end-user authentication using JWT tokens. Where you can use the fields in JWT to authenticate the user --- ## Configuring authorization - Who can talk to whom - Uses RBAC (role-based access control) - Service role - Actions that can be performed on service by any principal with the role - Service role binding - Assigns roles to principals (principals = service identities = ServiceAccounts) ??? Once you have an authentication policy in place, you want to control which services can talk to each other. To do that you need to describe a service-to-service communication policy. This is done using RBAC - role based access control. There are two objects you use to define a policy: 1. Service role: this one describes actions that can be performed on a set of services with any principal that has the role 2. Service role binding: this one is used to assign roles to a set of principals. --- ## Configuring RBAC - ClusterRbacConfig resource (`rbac.istio.io/v1alpha1`) - Multiple modes: - On, off - On with inclusion, on with exclusion ??? Just like with mTLS, there's an ClusterRbacConfig resource that can be used to turn on or enable RBAC. It supports multiple modes: - ON: requires RBAC policies for communication - OFF: RBAC is not required, this is the default - on with inclusion: you can define the set of namespaces/services in the policy where RBAC is required - on with exclusion: you can define the set of namespace/services in the policy where RBAC is not required. So RBAC is on for everything except the namespaces declared in the policy To do a gradual roll out of RBAC you should use ON with inclusion mode first. Then as you define policies for your services, add it to the inclusion list. This allows you do enable RBAC for each service separately, without breaking anything. --- class: middle,center # Exercises - Security ### `./istio/security` .big[https://github.com/peterj/jfuture] --- ## Istio vs. Linkerd vs. Consul Connect? - Linkerd: Kubernetes only - Consul: agent per-node + proxies - Linkerd: no circut breaking* - Consul: no failure injection .footnote[https://github.com/linkerd/linkerd2/issues/2846] ??? - Istio + consul support VMs as well - Consul runs an agent for every Kubernetes node - All meshes support mTLS and certificate management - Support for all communication protocols: TCP, HTTP, grpc - consul also doesn't have failure injection - as for monitoring and observability, all are pretty much on par - also linkerd doesn't have support for multicluster (YET!) --- ## How to get started? - Do you need a service mesh? - Start small and slow: - Learn and understand the resources - Apply to a subset of services - Understand the metrics, logs, dashboards - Repeat .footnote[https://istio.io] --- name: thankyou ## Thank you .center[### FEEDBACK https://forms.gle/xJW4TVqCfXbhTftm8] **Slides**: https://slides.peterj.dev/jfuture-2019 **Exercises**: https://github.com/peterj/jfuture **Contact** - [@pjausovec](https://twitter.com/pjausovec) - [peterj.dev](https://peterj.dev) --- name:toc ### Table of Contents .small[ - [Introduction to Containers](#intro) - [Docker Overview](#docker) - [Kubernetes Overview](#kubernetes) - [Service Mesh](#service-mesh-overview) - [Traffic Management](#traffic-management) - [Resiliency](#resiliency) - [Security](#security) ]